
#8: Rust: Comprehensive Rust, Arroyo, Müsli and Typical
a Google internal Rust course, a stream processing engine, a serde alternative and a modern data serialization framework

Welcome to Behind the Mutex! Our weekly newsletter summarizes notable activity in open-source, new and growing projects and releases.
In Case You Missed It
Explore the EVA codebase in our latest review:

The previous issue of our weekly newsletter:

Open Source Landscape
Behind the Mutex picks a few categories and explores new and popular projects and features there.
Comprehensive Rust: https://github.com/google/comprehensive-rust
Comprehensive Rust is a three day Rust course developed by the Android team which is used internally at Google when teaching Rust to experienced software engineers.
The course covers the full spectrum of Rust, from basic syntax to advanced topics like generics and error handling. Its goals are:
To give you a comprehensive understanding of the Rust syntax and language.
To enable you to modify existing programs and write new programs in Rust.
To show you common Rust idioms.
The first three days show you the fundamentals of Rust. Following this, you’re invited to dive into one or more specialized topics:
Android: a half-day course on using Rust for Android platform development (AOSP). This includes interoperability with C, C++, and Java.
Bare-metal: a full day class on using Rust for bare-metal (embedded) development. Both microcontrollers and application processors are covered.
Concurrency: a full day class on concurrency in Rust. We cover both classical concurrency (preemptively scheduling using threads and mutexes) and async/await concurrency (cooperative multitasking using futures).
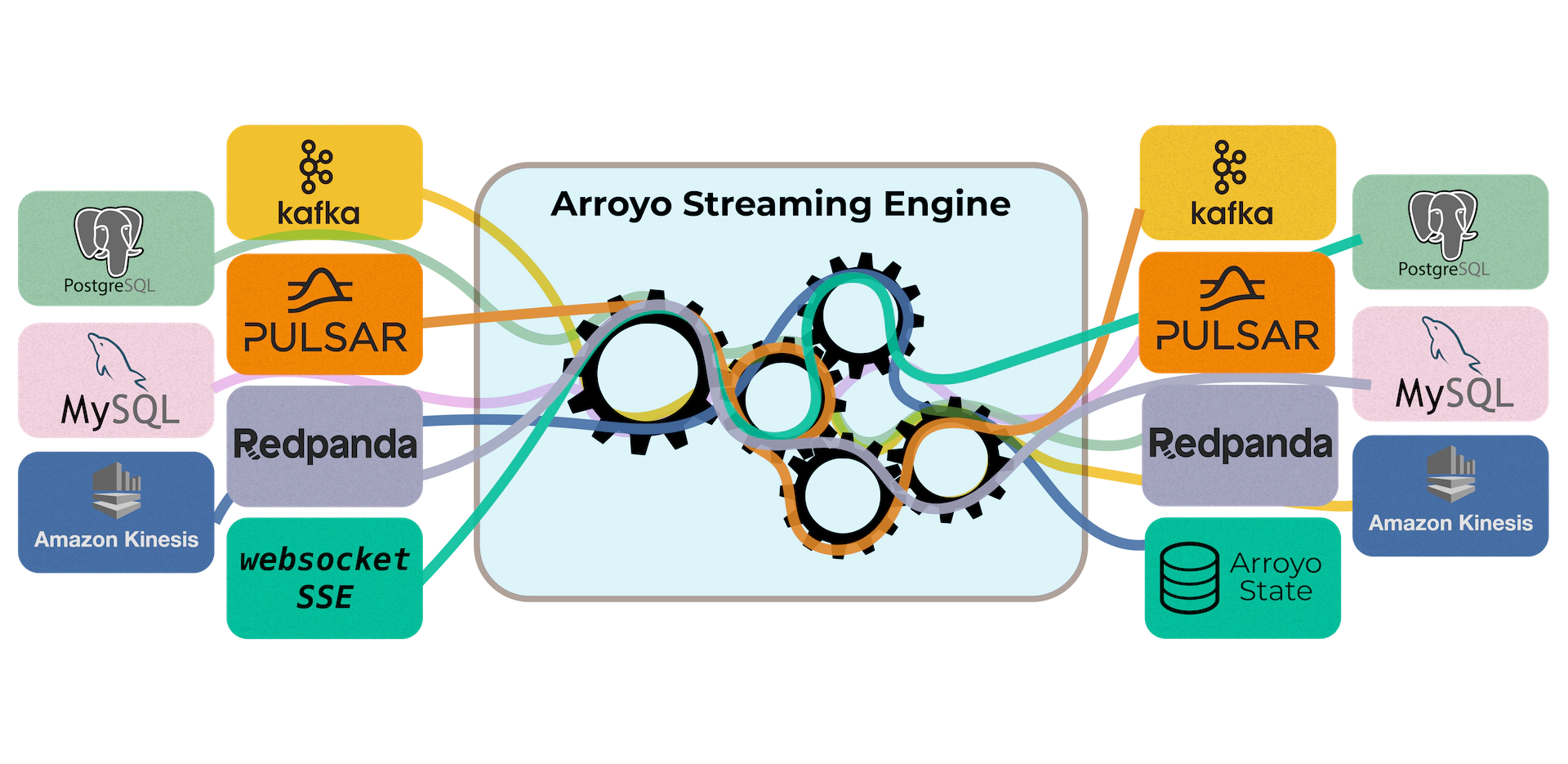
Arroyo: https://github.com/ArroyoSystems/arroyo
Arroyo is a distributed stream processing engine written in Rust, designed to efficiently perform stateful computations on streams of data. Unlike traditional batch processors, streaming engines can operate on both bounded and unbounded sources, emitting results as soon as they are available. Some use cases include:
Detecting fraud and security incidents.
Real-time product and business analytics.
Real-time ingestion into your data warehouse or data lake.
Real-time ML feature generation.
Arroyo comes with a number of features that stand out from other popular streaming engines:
High performance SQL is a first-class concern. Arroyo lets you build streaming pipelines by writing the same analytical SQL queries you are already running in your data warehouse, with a few real-time-specific extensions for stateful operations such as windows and joins. This significantly lowers the entry bar for building real-time data pipelines.
SQL user-defined functions (UDFs) in Rust.
Serverless operations. The system is designed to run in modern cloud environments, supporting seamless scaling, recovery, and rescheduling. Kubernetes and Nomad deployments are available.
Web Console. The UI allows configuring the system, setting up connections to sources and sinks and managing pipelines.
Kafka, Redpanda, PostgreSQL, MySQL and Server-Sent Events sources are supported out of the box. The Amazon Kinesis connector is coming soon.
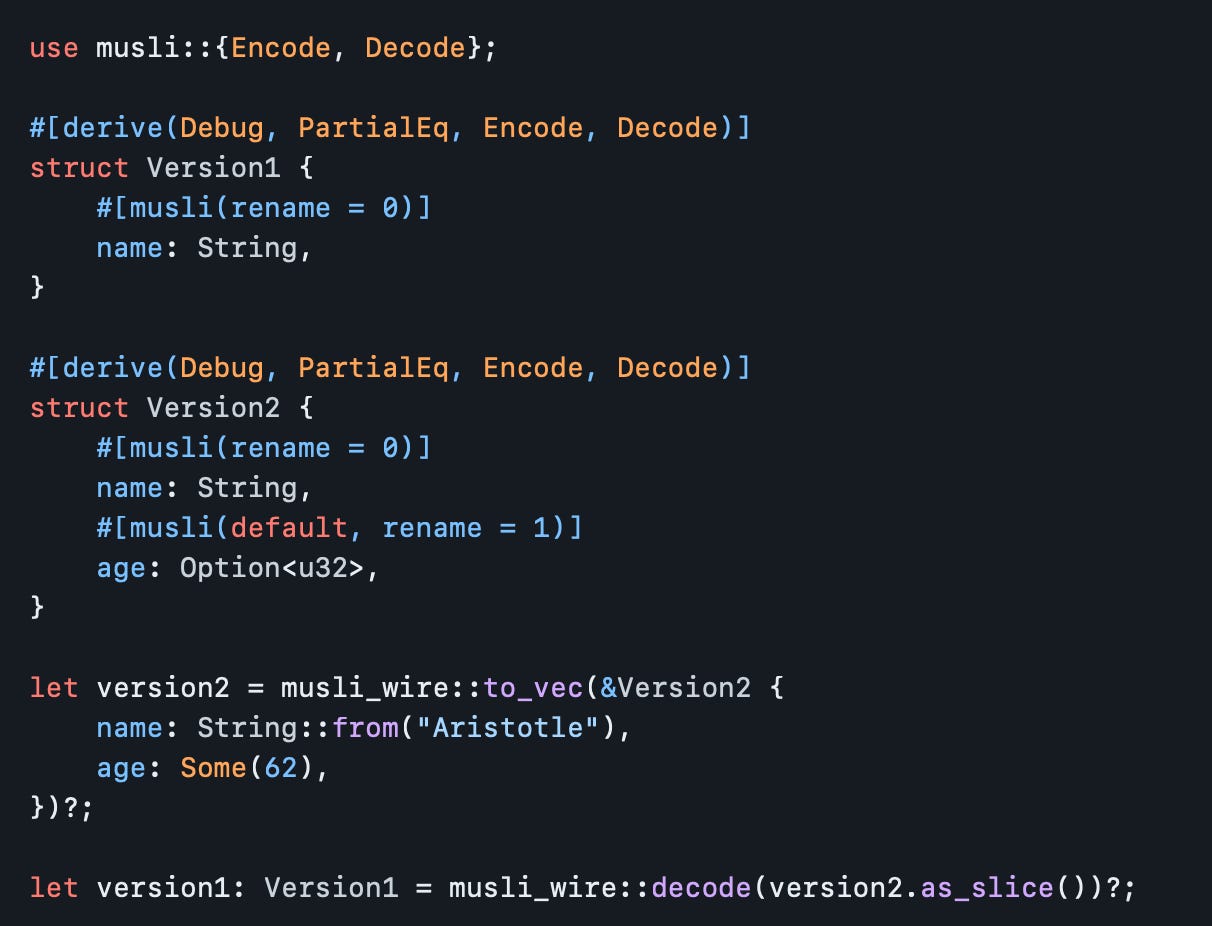
Müsli: https://github.com/udoprog/musli
Müsli is a flexible, fast, and generic binary serialization framework for Rust, and is designed on similar principles as serde, relying on the language’s powerful trait system to generate code which can largely be optimized away. Some of its design considerations are:
Use of generic associated types for narrower abstractions.
Sparing utilization of the Visitor pattern when it is unnecessary
Introduction of modes that allow changing the way models are serialized. Instead of defining distinct models, encoders can be configured to apply different encoding attributes.
The crate provides a set of formats, each with its own well-documented set of features and tradeoffs. The formats differ in the way how they support backward and forward compatibility and whether the resulting payloads are self-descriptive (and don’t require models to decode and can be dynamically introspected, e.g. musli-json).
Typical: https://github.com/stepchowfun/typical
Typical offers an alternative to data serialization frameworks such as Protocol Buffers and Thrift by supporting a more modern type system based on algebraic data types. This promotes a safer programming style with non-nullable types and exhaustive pattern matching.
The framework solves the backward- and forward-compatibility challenge by introducing asymmetric fields. To help you safely add and remove required fields, Typical offers an intermediate state between optional and required: asymmetric. An asymmetric field in a struct is considered required for the writer, but optional for the reader. Unlike optional fields, an asymmetric field can safely be promoted to required and vice versa.
Similarly to the mentioned popular frameworks, Typical generates code based on the specified schema. The schema language is on par with Protocol Buffers, supporting imports, built-in types, user-defined types, choices and much more.
struct SendEmailRequest {
to: String = 0
# A new asymmetric field
asymmetric from: String = 3
subject: String = 1
body: String = 2
}Rust, JavaScript and TypeScript are the languages currently supported by the Typical code generator.
If you have any feedback or would like to see certain open-sources projects highlighted in our upcoming summaries and reviews, please feel free to comment, send an email or DM the author on Twitter @dalazx.
Until next Tuesday,
Behind the Mutex.