
#7 Databases: KeyDB, JunoDB, QuestDB and SpiceDB
a multi-threaded Redis fork, a battle-proven key-value store, a time-series columnar database and an access management DBMS

Welcome to Behind the Mutex! Our weekly newsletter summarizes notable activity in open-source, new and growing projects and releases.
In Case You Missed It
Explore the EVA codebase in our latest review:

The previous issue of our weekly newsletter:

Open Source Landscape
Behind the Mutex picks a few categories and explores new and popular projects and features there.
KeyDB: https://github.com/Snapchat/KeyDB
Who has not used Redis? The famous in-memory key-value database has been around since 2009 and helped to solve countless amount of problems in all sorts of engineering organizations and use-cases. Redis has a single-threaded event-driven architecture which from one side addresses both performance issues and code complexity, but introduces certain limitations from the other.
KeyDB, now with a completely open-source codebase, is a Redis fork maintained by Snap Inc. KeyDB meticulously follows the steps of its upstream and is considered to be a drop-in replacement, offering a superset of functionality on top of the Redis protocol, modules, scripts and atomicity guarantees. And here is why it stands out:
Multi-threaded architecture leveraging Multi Version Concurrency Control (MVCC) allows delivering a significantly higher performance per node, achieving up to 5x greater throughput in comparison to vanilla Redis.
Non-blocking KEYS, SCAN and other operations thanks to concurrent access to snapshots in MVCC.
Cross-regions multi-master support using asynchronous replication with a last write wins methodology.
More granular EXPIRE supporting set members.
ModJS, a scripting module based on V8 JIT, which is a more performant replacement to LUA.
Flash storage provider. Store your data beyond the available memory capacity.
Impressive roadmap which includes multi-tenancy support, JSON and RAFT.

JunoDB: https://github.com/paypal/junodb
PayPal just announced that they had open-sourced their battle-proven distributed key-value store that powers most of their critical services. JunoDB is a NoSQL solution that supports many use cases, including caching, idempotency, counters, system of record and more.
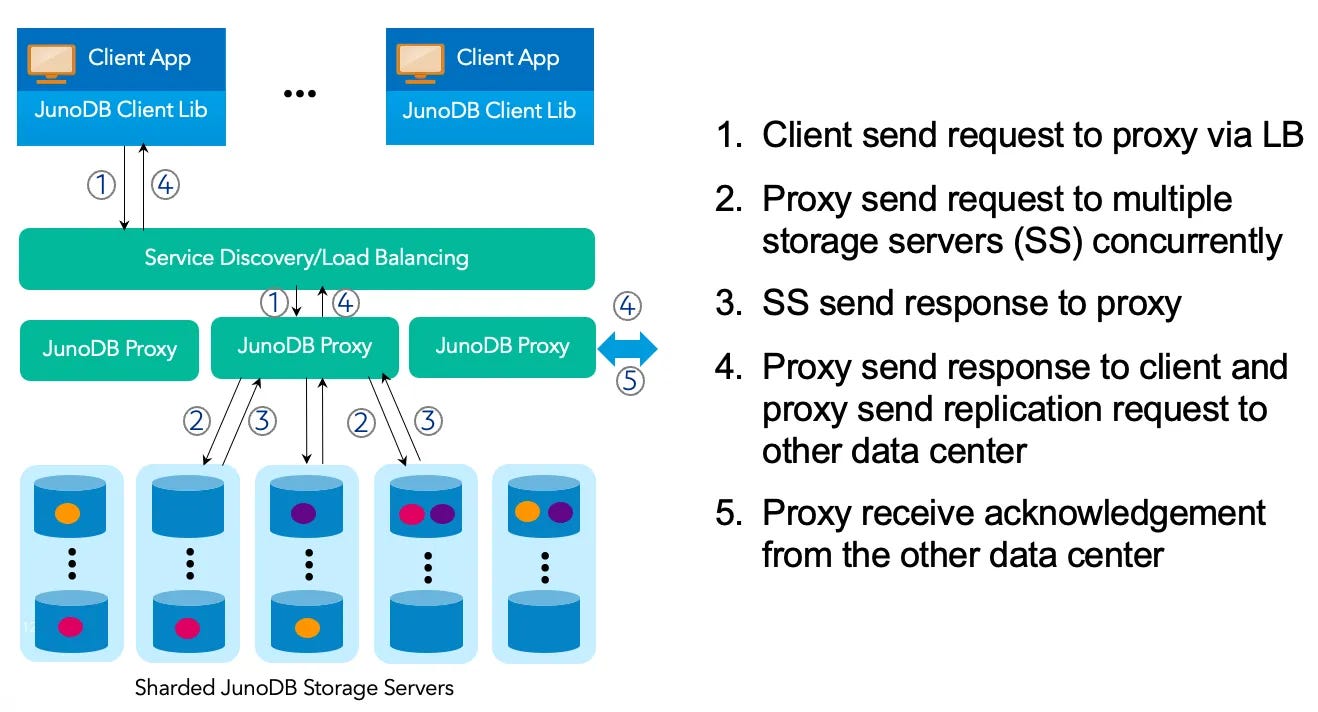
Reliable. PayPal’s deployment of JunoDB shows 99.9999% availability while serving 350 billion requests daily. This is achieved by employing within- and cross-datacenter replication and certain failover strategies.
Consistent. A quorum-based protocol and two-phase commit ensures data consistency across the deployment.
Secure. Data is secured both in-transit and at rest.
Scalable and Performant. JunoDB’s layered architecture splits responsibilities of keeping client connections and storing data into separate layers that can scale independently, achieving near-linear scalability, low latency (single digit millisecond response times) and high throughput.
QuestDB: https://github.com/questdb/questdb
Looking for a time-series relational database? QuestDB offers a solution to address many popular use-cases related to time-series and event data such as monitoring and real-time analytics, financial market data processing and industrial analytics.
To achieve its goals QuestDB extends ANSI SQL by introducing the LATEST ON , SAMPLE BY clauses and timestamp-native operators which enable users to write sophisticated time-series queries with ease.
This column-oriented database implements PostgreSQL Wire protocol and HTTP REST API as its primary means of communication. InfluxDB Line protocol is also supported for fast data ingestion.
QuestDB comes with a Web console that brings reacher interactive capabilities for exploring schema and data. With the help of the console, users can navigate the schema, build and test queries, visualize results, import and export data.

The product integrates with many popular tools for data ingestion and processing, including Flink, Kafka, Redpanda, Spark and more.
SpiceDB: https://github.com/authzed/spicedb
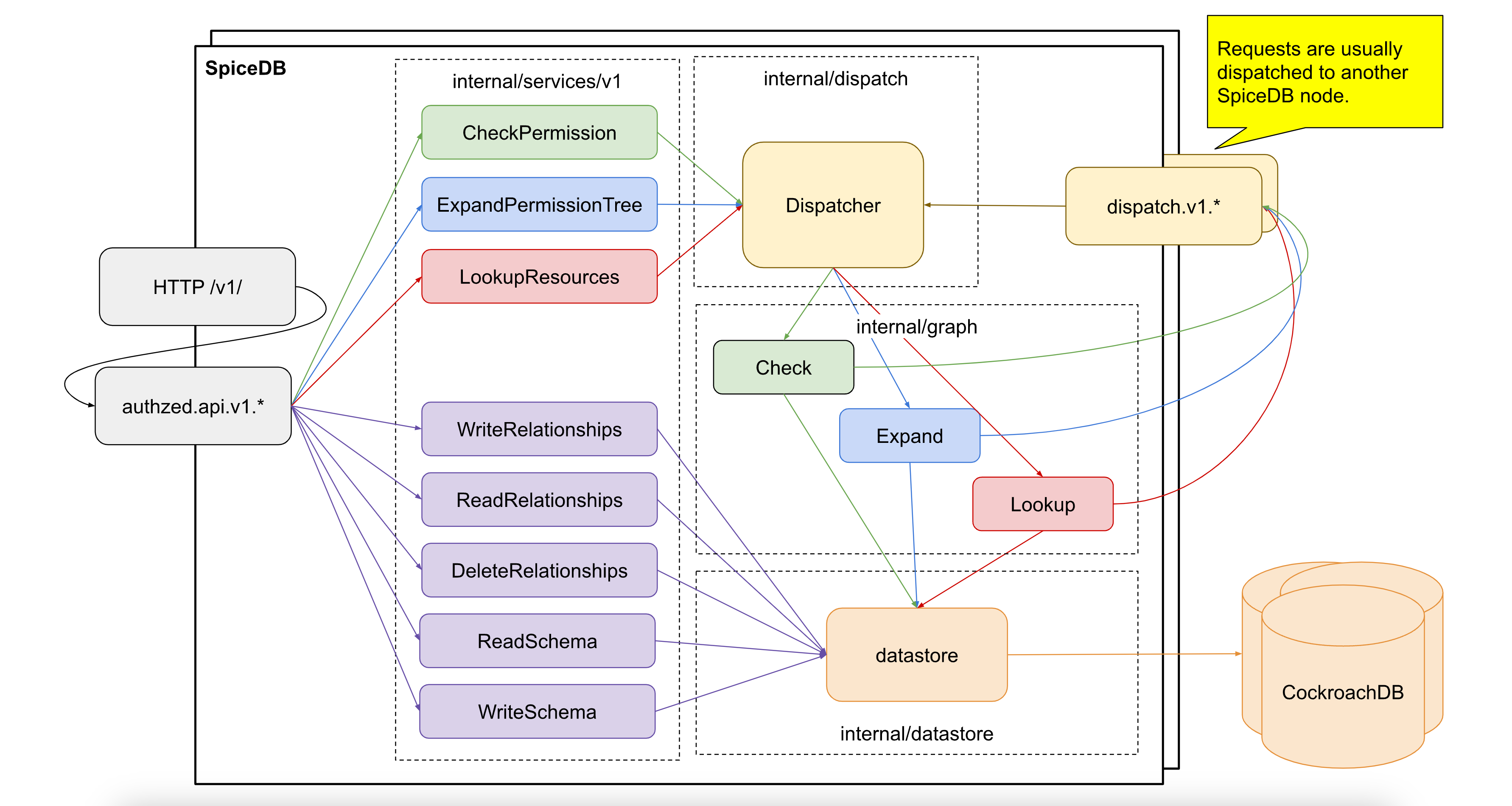
SpiceDB is a specialized database system for security-critical fine grained permissions checking, inspired by Zanzibar, the Google’s Global Authorization System.
Most of applications our there need at least some level of access management and permissions enforcement, and it is one of the first requirements for enterprise-grade software. SpiceDB elegantly solves these problems using its object relational schema definition, graph-based permission lookups and a number of supported persistent data stores. Organizations can implement ACL, ABAC, RBAC and any other custom strategies for managing access to resources.
SpiceDB acts as a centralized service that stores authorization data for further querying. The product serves well-documented gRPC and REST APIs for managing and checking permissions. This enables users to generate client libraries for programming languages of their choice.
The system uses a special language that allows configuring a schema to define the types of objects found, how those objects relate to one another, and the permissions that can be computed off of those relations.
definition blog/user {}
definition blog/post {
relation reader: blog/user
relation writer: blog/user
permission read = reader + writer
permission write = writer
}Once the schema is applied, the system can be populated with actual relationships that will further be used to check whether a given subject has a specified permission on a resource.
check resource:someresource view user:goog|12345Among the supported persistent data stores are CockroachDB, Spanner, MySQL and PostgreSQL.
If you have any feedback or would like to see certain open-sources projects highlighted in our upcoming summaries and reviews, please feel free to comment, send an email or DM the author on Twitter @dalazx.
Until next Tuesday,
Behind the Mutex.