
REVIEW: LangChain
Deep dive into the most popular library for building LLM-driven applications
https://github.com/hwchase17/langchain: v0.0.143 dated April 18th 2023
LangChain is a relatively new project that gained its popularity on the wave of significant developments in the space of large language models (LLMs). As of the time of this writing, its GitHub repository has 28.3k starts and 2.8k forks. This is staggering, because there are lots of other Python projects out there that pragmatically have way more impact, are quite mature and battle-proven, but are not even close to these numbers.
So, what is LangChain? It is a library for building LLM-driven applications. Some examples of such apps are
question answering and information retrieval
chatbots and personal assistants
interacting with 3rd-party APIs, and more
The library offers a suite of components that the client can configure, extend and combine into so-called chains that can be run to achieve specific goals. Some of the major classes of components are Prompts, LLMs, Chains, Agents and Memory.
Let’s grab an example and see how it works.

If you naively assumed that the example would just work, the reality is harsh. This example from the documentation fails right away while importing its modules. The reason is that there’s a missing dependency. Some Prompts require jinja2 although it is optional according to pyproject.toml. Although you may think that this is a minor issue and we should not focus on this, in fact, this highlights a way bigger issue.
Such a silly bug can only happen within a PyPI release if there are no means to enforce quality of the project and its codebase. In other words, no tests or no CI whatsoever. And indeed it is the case. In our weekly brief #1 we already warned about the quality of the LangChain project and the inherent risks of using it in production.
A lot of pull requests are merged without any changes to existing tests, not to mention new tests. Instead, the contributors patch Jupyter notebooks that serve both as some kind of smoke tests and a source of documentation for their changes. Obviously this is not what the software engineering community would expect from such a popular codebase.
For those who still need to integrate LangChain into their systems, one piece of advice would be to at least pin the version of the package (as you should probably do regardless) so that any new untested releases would not cause any major outages.
Now back to our example. The whole idea behind it is to show that one can define an agent instrumented with a LLM and capable of utilizing a certain set of tools in order to find the answer to the request. Our set of tools includes serpapi and llm-math which are responsible for searching the Web and performing math calculations correspondingly.
Our request is to get the yesterday’s temperature in San-Francisco in Fahrenheit and raise the number to the power of 0.023. Pretty artificial, but that will do.

Now you may be wondering why would the underlying LLM decide to convert Fahrenheit to Celsius if the request was to actually use Fahrenheit. That’s a separate topic. You may also be wondering why the output formatting is lacking a few newline characters and hence some lines are crammed with both inputs and outputs. That is directly related to the project’s quality issues which were brought up earlier.
We are interested in how this chain of thought works in the first place and what drives it. Intuitively we understand that the fundamental driving forces are LLMs and Prompts, and that the rest is built on top of these, right? Let’s briefly explore the code behind these to be able to grasp more complex concepts.
Prompts
LangChain provides a simple abstraction around string templates. BasePromptTemplate has two abstract methods to implement and PromptTemplate does exactly that using either f-strings or jinja2. There’s nothing special about it. The whole idea is to define a PromptTemplate and then render it using the user’s input or output from a LLM or a Tool. Later in the post you will see some examples of the built-in prompts that LangChain offers.
langchain/prompts/base.py#L68

Models
Now that we have means to format Prompts, let’s also check how the library abstracts away LLMs and feeds those Prompts to obtain predictions. Similarly to Prompts, there is an abstract interface to implement for any given model.
langchain/llms/base.py#L56
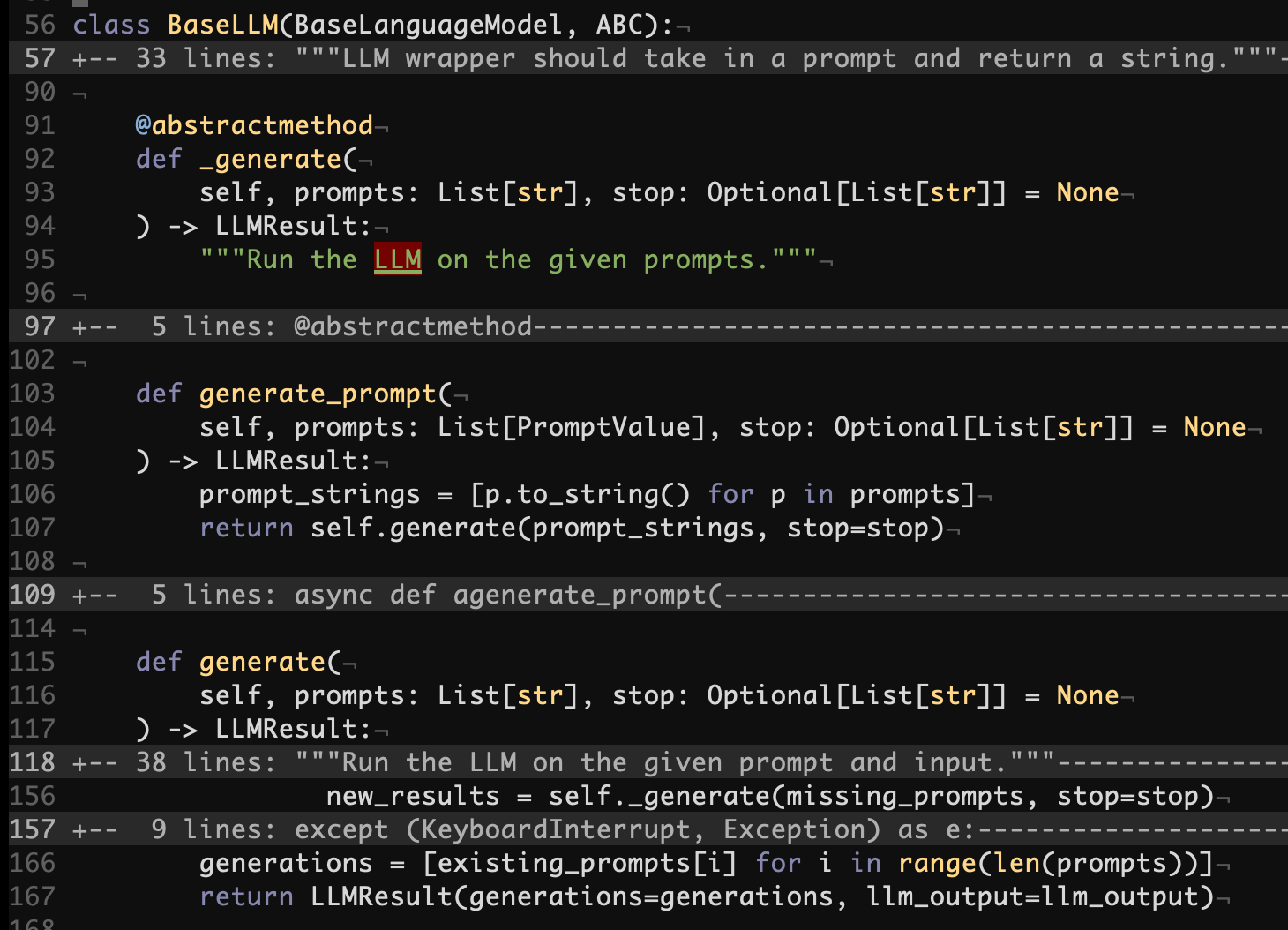
LangChain is equipped with a few dozens of implementations of BaseLLM/LLM and you can expect all of them to have their corresponding _generate methods.
Note that LLMs expect rendered prompts - they never render them themselves. So where do prompt rendering and LLM feeding happen? In Chains.
Chains
What is a Chain? It is an abstract class with three abstract methods to implement: input_keys, output_keys and _call. Basically it is an abstraction over a function that receives an Any and returns a Dict, with some validation and tapping into BaseMemory.
You can perceive it as a composition primitive. There are built-in Chains such as SequentialChain and many others which combine multiple Chains into a single one.
langchain/chains/base.py#L20

One of the fundamental Chains is LLMChain. It combines a Prompt and a LLM. Below you can see that this is exactly where the prompt gets rendered before it is passed to the LLM.:
langchain/chains/llm.py#L15

Many of the built-in Chains in LangChain rely on LLMChain. They would render their domain prompts with the given input, run the rendered prompts through the LLM and then parse the output into whatever the clients expect.
Having seen these basic components, it is time to dive into something more complex.