


REVIEW: Jina. Part 1. Clients
A Python framework for building AI services and pipelines

https://github.com/jina-ai/jina: v3.19.1 dated July 19th 2023
When it comes to machine learning model serving, there are plenty of open-source solutions that address this problem to different extents and from various angles.
Some of those solutions put stronger emphases on developer experience and interoperability. Others focus more on infrastructure, observability and scalability. Some care deeply about performance. This leads to different learning curves for initial integration of those tools, as well as following maintenance efforts.
In this deep-dive review, we are going to explore Jina, a Python framework for building multimodal AI services and pipelines. At its core, the framework might be considered as an alternative to more conventional manually-built general-purpose gRPC/HTTP servers, but it offers a distinct set of ready-to-use features that set it apart:
Multimodal data support, integrating seamlessly with the extensive Python and machine learning ecosystems.
Interchangeable support of popular application-level protocols such as gRPC, JSON over HTTP and WebSockets.
Cloud-native deployments to Kubernetes and Docker Compose.
Integrated support of OpenTelemetry.
Stateful replication capability based on RAFT. This allows developers to build sophisticated applications on par with distributed databases. One great example that leverages this feature is vectordb, a new product by Jina AI.
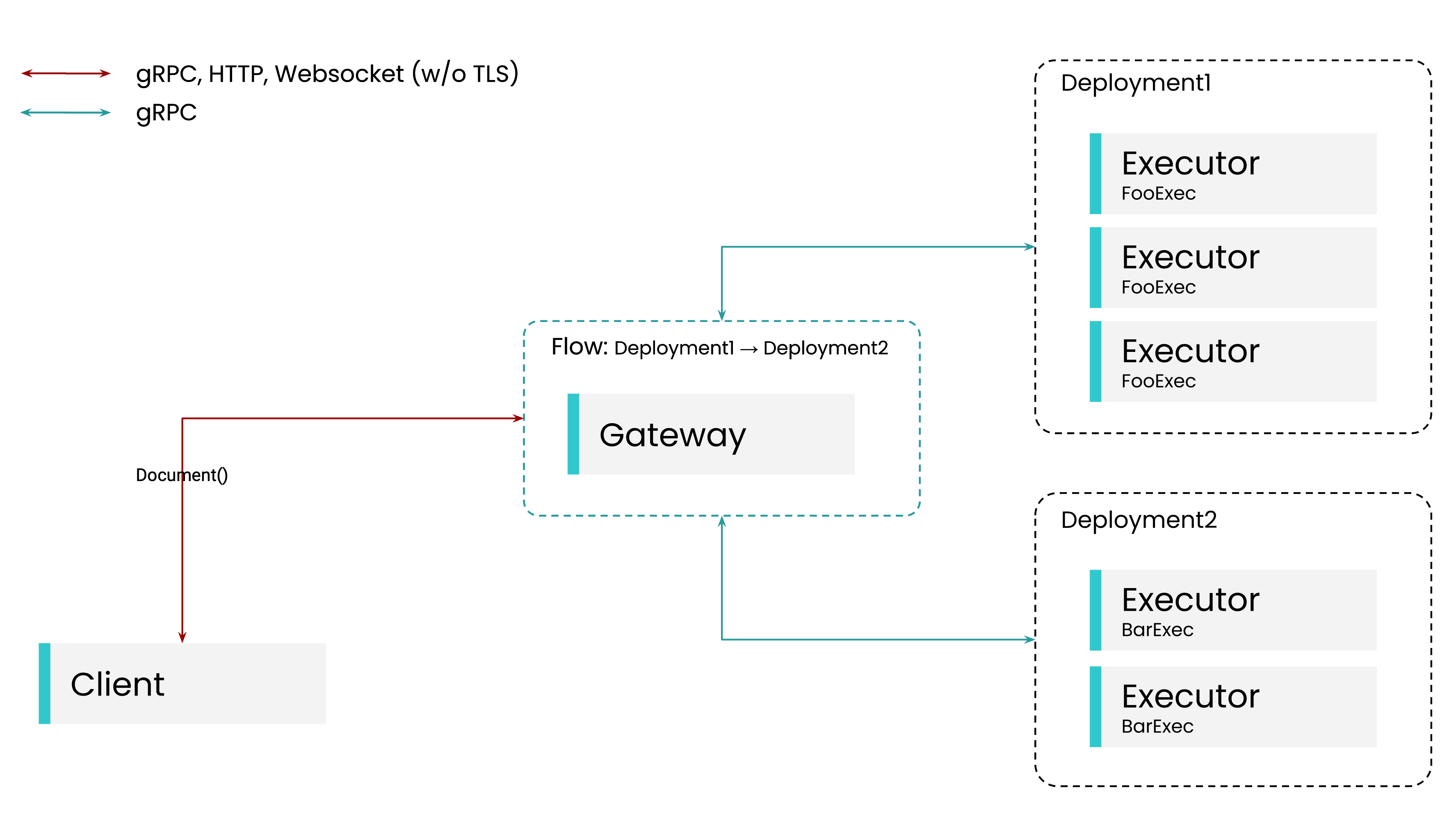
Jina allows developers to define network services, called Executors, with an opinionated interface based on DocArray, a Python library for handling multimodal data. Executors operate on lists of documents. An Executor receives documents, transforms them according to its logic and then returns the resulting documents. Such an interface facilities composition of Executors into so-called Flows, machine learning inference pipelines that allow chaining Executors in order to serve more complex processing scenarios in a decoupled manner. The interface is pretty generic and can accommodate many use-cases.
Jina’s Gateway component is responsible for exposing endpoints for the aforementioned protocols and coordinating communication between Executors within Flows. Different Executors can be scaled independently within dedicated Deployments.
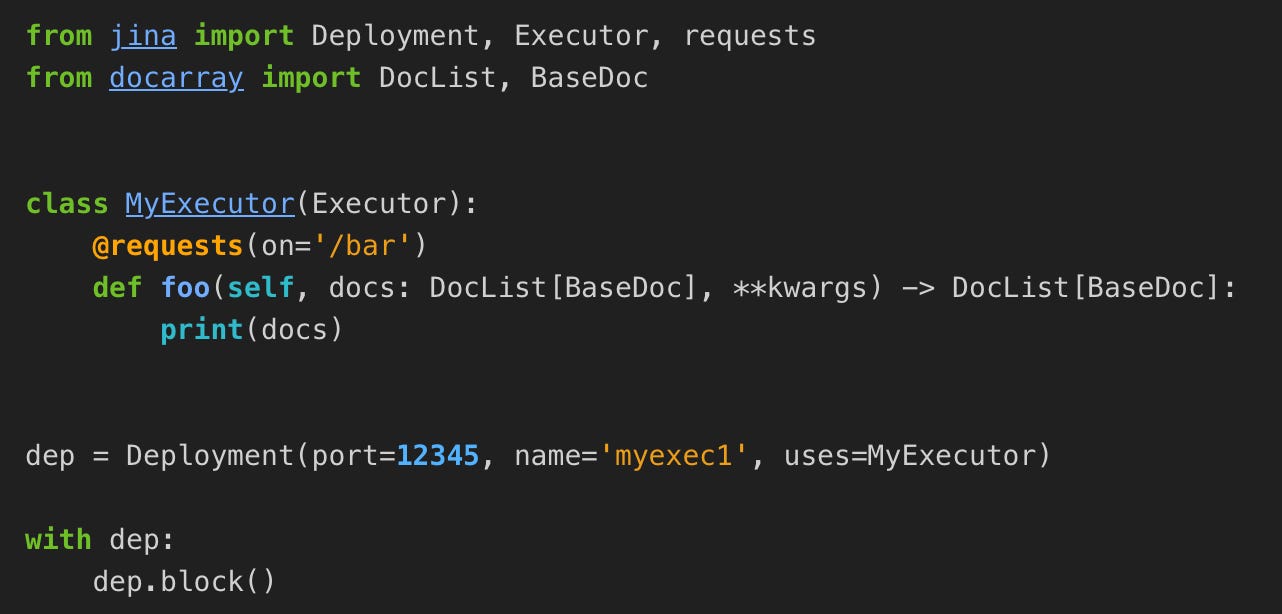
Jina offers an SDK and CLI to translate declarations of Deployments and Flows into Cloud-native configurations. This is the primary way of running Jina applications in production. A typical workflow might look as follows: a user defines one or more Executors, optionally combining them into a Flow. This allows the user to test the whole setup locally. When it is time to deploy the setup, the user generates Kubernetes resource definitions using the SDK/CLI, adjusts them as needed and applies agains their target Kubernetes cluster.
The process above is a bit involved. The user should definitely know what they are up to, as well as to have at least some experience working with Kubernetes. It is also worth mentioning that Jina requires Kubernetes to be equipped with a service mesh such as Linkerd, and the generated resource definitions will rely on its functionality.
There’s a lot to cover in this product, thus we decided to split this review into multiple parts focusing on specific components. The first part of the review will be exploring Clients. Whether the user tests things locally or integrates Jina into the rest of their systems, they use a Client to interact with their deployed Executors via a Gateway.
Clients
Jina’s Gateway component exposes multiple application-level protocols: gRPC, JSON over HTTP and WebSockets. For users’ convenience the product comes with its own implementations of Clients for the corresponding protocols for Python.
Before we dive into the code, let’s keep in mind some key expectations that one might have towards a production-ready SDK and Client: solid quality, sufficient performance and a relatively stable interface.
So, how to instantiate a Client?
jina/clients/__init__.py#L75
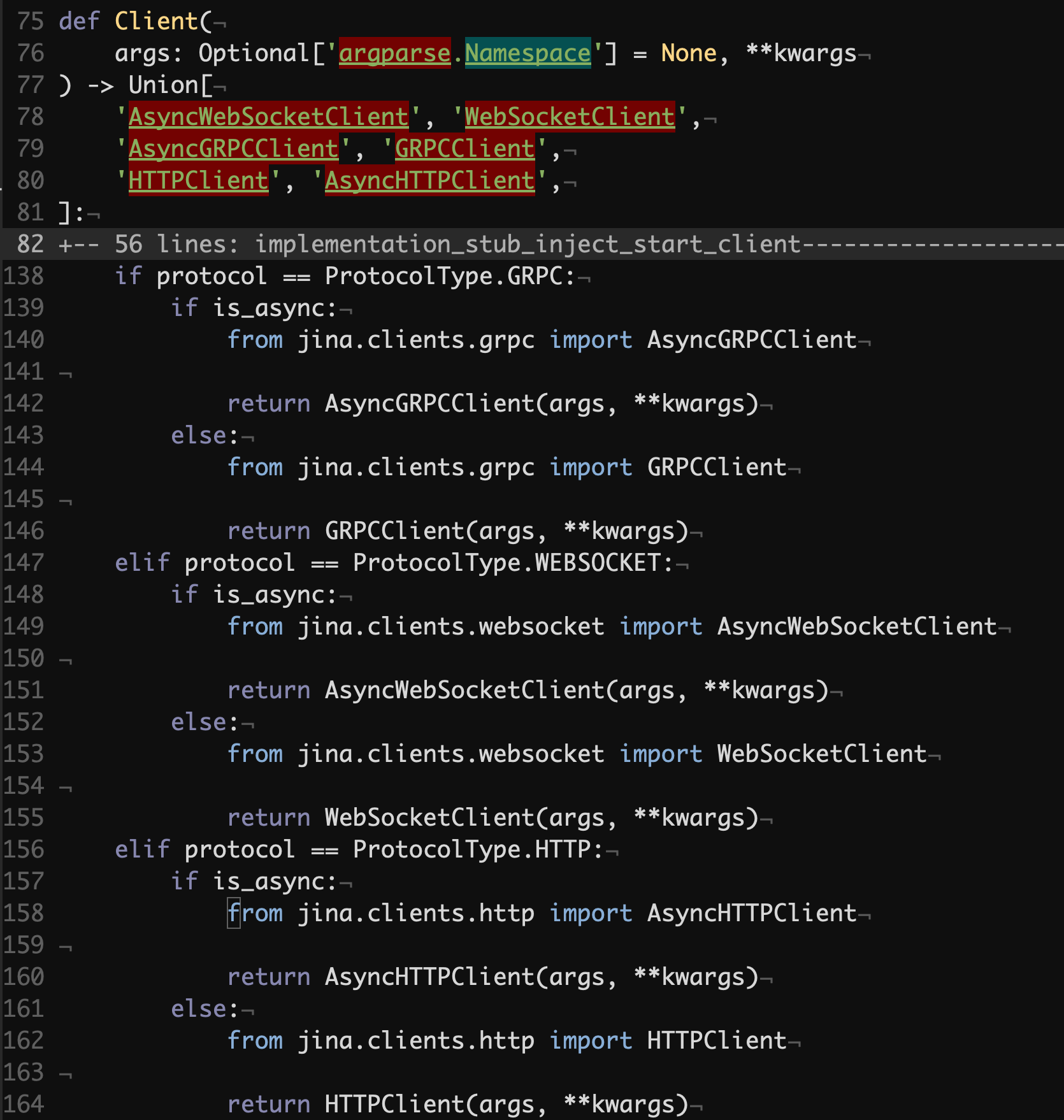
The Client function is a factory that creates instances of Jina clients based on the specified protocol and concurrency model.
Note that typing-wise the codebase is not doing that great. Here, for example, we could’ve expected to see a number of @overloads to properly communicate which resulting type the developer will get given specific argument values. Otherwise we can assume that static type checkers in projects that rely on the Jina Client won’t be happy.
Let’s dive deeper into the client implementations of specific protocols, starting with gRPC.
jina/clients/grpc.py#L11

As you can see, both sync and async versions don’t have any implementation logic on their own, but instead they rely on the GRPCBaseClient superclass and differ by inheriting certain mixin classes. Even judging by the names of the mixin classes, they in turn should implicitly rely on GRPCBaseClient or its superclasses, and in fact it is the case.
The mixin pattern is quite popular in Python, but in our view it is more damaging than helpful:
It goes agains common object-oriented principles. It abuses inheritance in favor of proper composition.
It forces to write mixin code with implicit assumptions. For example, assuming that a class that the mixin is added to has certain external and internal attributes available within the mixin code, even though they are not declared anywhere.
Because of the points above, the code becomes harder to read and reason about. This jeopardizes one of the fundamental principles of software engineering: that we write good code first and foremost for people to comprehend and communicate, and then for machines to execute, not vice-versa.
Additionally, likely static type checkers will also be confused by those undeclared attributes.
One peculiar thing in the definition of the two gRPC classes is that they both subclass GRPCBaseClient. Hence the superclass supports both sync and async concurrency models. Let’s find out how it is done.
GRPCBaseClient implements two abstract methods of the BaseClient class. Same applies to HTTPBaseClass. It seems that the grand idea behind the mixins above is that PostMixin, AsyncPostMixin and others are reused across the implementations of BaseClass, although it is done totally implicitly by relying on those abstract methods.
Here’s GRPCBaseClient._get_results that is the powerhouse of almost all GRPC calls:
jina/clients/base/grpc.py#L22
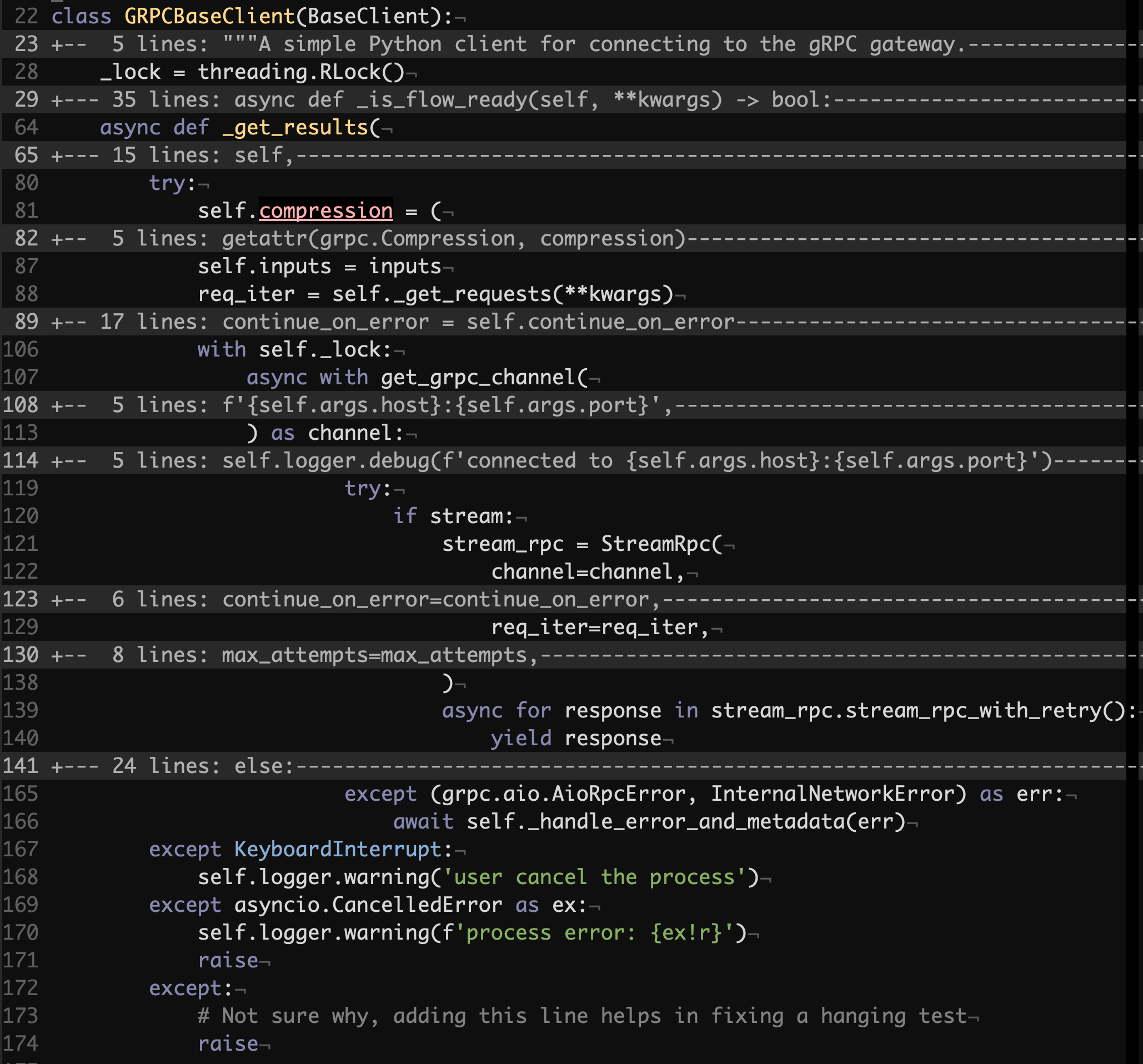
That’s one pretty long and nested method. We can review it step by step.
We can see two assignments to self.compression and self.inputs which simply don’t belong there. The values are calculated from the method parameters, but semantically such a state should not be stored by that method. The reason behind these assignments, and in part the self.inputs one, is that the subsequent call to self._get_requests relies on that state. It might be that one wouldn’t be too worried about this in an asynchronous code, unless they see a statement for acquiring a threading reentrant lock right after.
If someone consciously put that lock there, acknowledging that multiple threads might be competing over an asynchronous method, why the lock does not cover the assignments and the call to self._get_requests which almost guarantee issues in a concurrent environment? Too many mysteries already, but it’s not over yet.
Where is the lock defined? In the class body. What does this lead to? It makes it impossible to efficiently use distinct instances of GRPCClient in separate threads.
Now we are getting onto something really interesting. Once the lock is acquired, the method creates a new gRPC channel. Right, a new channel on each call to _get_results. Hence a new connection, a new TCP handshake and a new TLS handshake etc. This is quite inefficient. The client does not manage to keep in its state what’s truly important, but keeps some obscure values that are never used.
It is impressive how much pain is concentrated in a single key method, but we have not even gotten to the piece of code that facilitates reuse of it in both concurrency models. You will be correct in your assumption that AsyncGRPCClient and the corresponding asynchronous mixins such as AsyncPostMixin will just use the code above as is. But let’s find out how it done for the synchronous counterparts.
jina/clients/mixin.py#L212
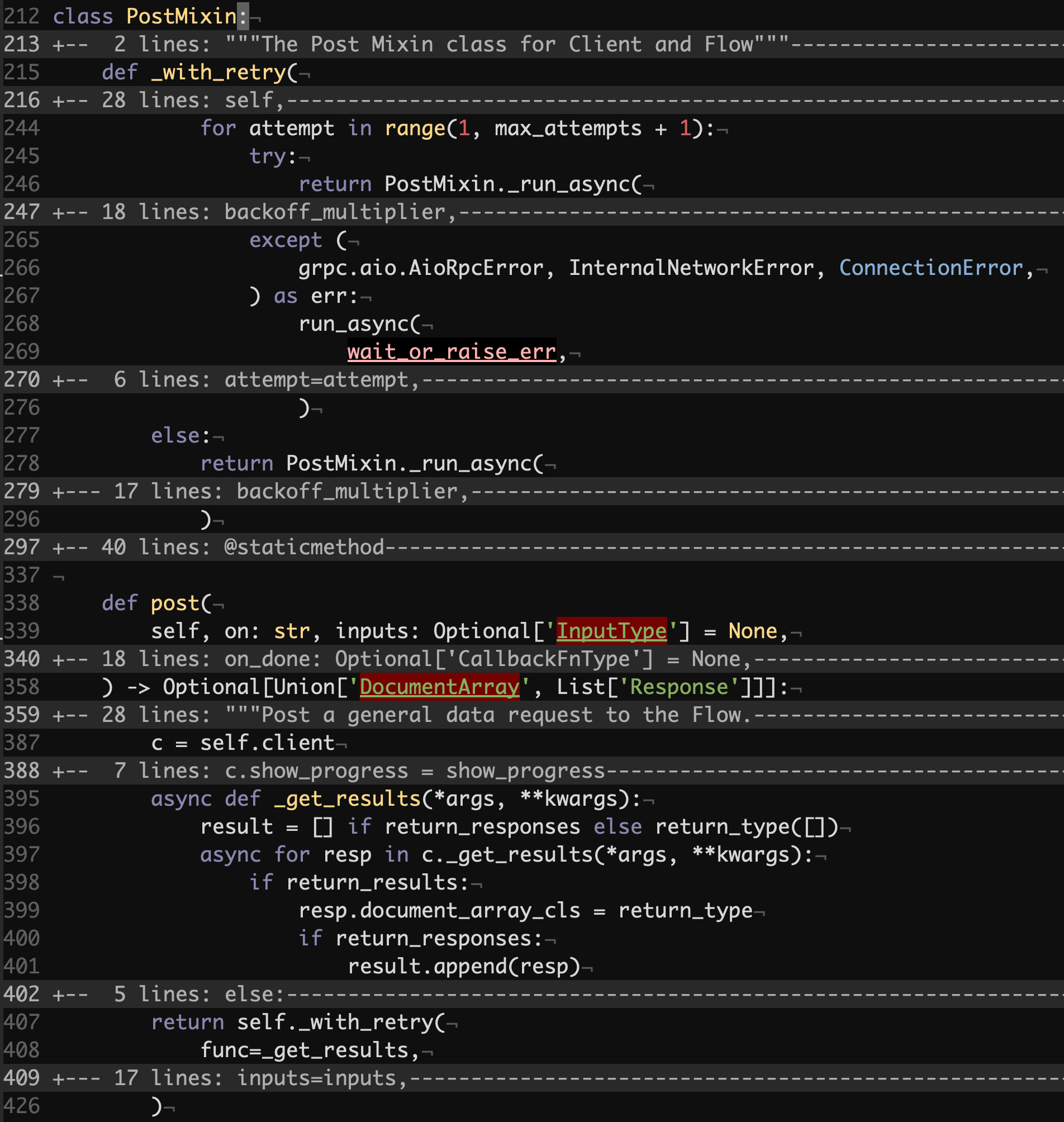
The post method in PostMixin is mixed in both GRPCClient and HTTPClient and is the key method for interacting with Jina Gateways and Executors by allowing users to push and pull documents in and out.
We see that there’s some retrying logic that we won’t dive into deeply, but we will rather focus on what gets retried. The post method defines an asynchronous callback called _get_results which then gets passed to _with_retry and subsequently to _run_async. PostMixin._run_async wraps the run_async function one-to-one.
jina/helper.py#L1277
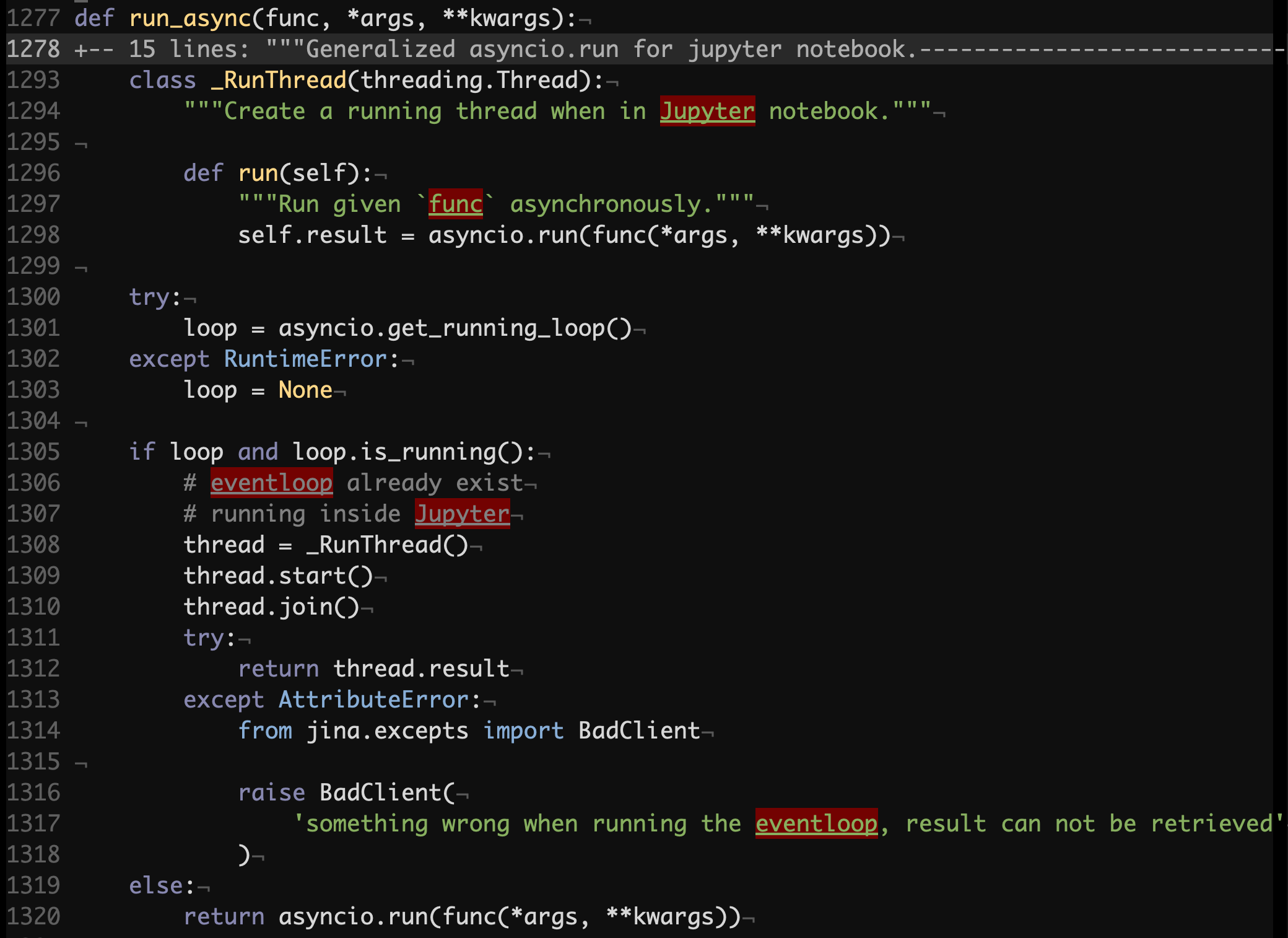
The most of the logic above addresses an issue which manifests in Jupyter since its runtime relies on a running event loop, while asyncio.run does not work if there is one. Jupyter is meant to be used interactively, therefore we won’t be considering performance implications of spawning a new thread on each call here.
What’s worth noting though is that in any case we see a call to asyncio.run to execute the func coroutine function. asyncio.run calls may not be as cheap as it seems as they start new event loops and then tear them down, which includes finalizing asynchronous generators and shutting down default executors if there were any.
Synchronous client implementations could have done so much better:
Manage the life-cycles of their internal event loops, keep references to them and reuse them.
Explicitly take care of synchronization between threads, and more.
But instead users are offered clients with questionable design and performance. The HTTP implementation is no exception as it has all the same issues as the gRPC one. This is a good example where design, which is done and driven for the sake of design, has negative effects on software. The performance was overshadowed by substandard patterns that only imitate code reuse. As it has been shared many times in our previous deep-dive reviews already, it is composition that you really want to apply in most cases, not inheritance.
This concludes the first part of our deep-dive review of the Jina codebase. The next part will be covering in detail its Gateway and Executor components. Stay tuned!
Until next time,
Behind the Mutex.