
REVIEW: Chroma - AI-native embedding database
Deep dive into new embedding database integrated with LLMs and LangChain

https://github.com/chroma-core/chroma: 0.3.21 dated April 5th 2023
According to its website and documentation,
Chroma is the open-source embedding database.
Behind the Mutex thinks that the definite article is no mistake in the previous sentence. In this post we will try to rip through the cover of Chroma’s marketing ingenuity and investigate why it is the one indeed.
What do you expect when you read a phrase like “embedding database”? Someone might confuse “embedding” with “embedded” and think about solutions such as SQLite and DuckDB. Surprisingly, to some extent these two terms both apply to Chroma.
The answer to the question why Chroma is the one is manyfold. First-off let’s try to figure out the project’s terminology and functionality. After that we’ll dive into its codebase and see how exactly it works.
So, “embedding database”. If you Google this phrase you won’t see anything meaningful out there. The search engine will suggest results covering “embedded databases” which are only minimally related to what Chroma does. You might think “who Googles nowadays?” and suggest asking ChatGPT:
An embedding database is a type of database that stores vector representations (also known as embeddings) of items such as words, images, or other types of data. These embeddings are created using machine learning algorithms that learn to map items to dense numerical vectors that capture their meaning or features. The embeddings can then be used for various tasks such as similarity search, recommendation systems, and natural language processing.
Some examples of embedding databases include:
1. Faiss - a library for efficient similarity search and clustering of dense vectors, created by Facebook: https://github.com/facebookresearch/faiss
2. ANN - Approximate Nearest Neighbors library that includes various index structures and algorithms to search for the nearest neighbors of a query point in a high-dimensional space: https://github.com/spotify/annoy
3. Elasticsearch - a search and analytics engine that can be used to store and search for vector embeddings: https://www.elastic.co/guide/en/elasticsearch/reference/8.7/dense-vector.html
Overall, embedding databases are becoming increasingly popular due to their ability to efficiently store, index and retrieve similar items in large datasets while also enabling various machine learning applications.
Everybody knows that GPT tends to make stuff up. When you ask it about vector databases you will get almost exact same answer and references. You might wonder what makes a vector database an embeddings database in the first place? We will try to answer this question using Chroma’s codebase. But for now we at least know that it is the embedding database: because why not.
Imagine that you had a relational database management system and you decided to store records about movies there. You would build a simple RESTful Web API that hides details about the underlying relational tables and how you query them. You would offer an SDK serving as a client to your API. And call it the film database, because you can. And ChatGPT would undoubtedly generate a nice answer for a query similar to the above example and even add references to IMDb, Rotten Tomatoes and more.
Now back to embeddings. Chroma offers a solution for document storage and semantic search over documents. The key use-case is serving a knowledge base and memory for LLM-based apps. Typically semantic search is implemented via finding nearest neighbor vectors in a vector space. Vector spaces are built from vectors, or embeddings, produced by transforming documents using a specific kind of machine learning models. Chroma tries to tie together both storing the documents and their corresponding embeddings for further search and retrieval.
Documents should be put into collections. Perhaps, what makes Chroma claim it is the embedding database is that users can declare new collections and specify the so-called embedding function that will be automatically used to obtain and store embeddings for new documents, and use the function to get embedding for search queries. Essentially users have a choice whether to obtain embeddings somewhere and manually store them along the corresponding documents, or try to embed this process into collections.
Now let’s try to see how Chroma works under the hood. The project consists of an optional RESTful Web API server in Python, and two clients in Python and JavaScript. The Python client works in two modes:
local, a self-sufficient mode that does not require a serverrest, a mode in which most of the work is offloaded onto the required server
The factory function Client chooses the implementation based on the settings provided.
chromadb/__init__.py#L59-L85

You may be wondering why you would need two implementations. This is interesting, because as you will soon see, the RESTful API server relies on the local implementation of the client. Let’s take a look at the rest one first:
chromadb/api/fastapi.py#L20
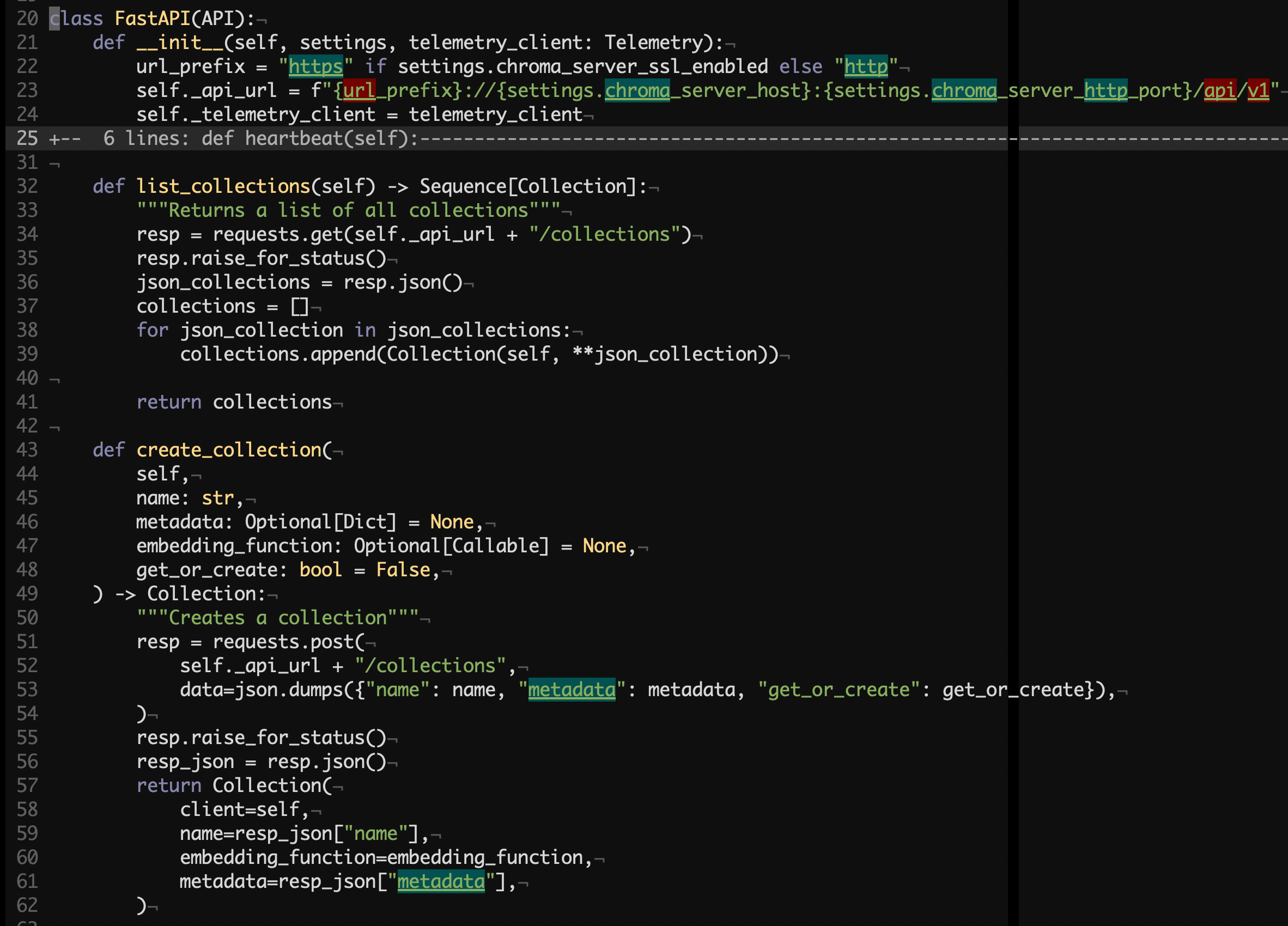
A few things to note right away.
The HTTP client is implemented poorly:
No way to keep a session with a pool of connections.
requestsestablishes a new connection on each request.No way to configure timeouts and other options.
Now what’s more interesting is specifically the create_collection method above. As mentioned previously, one interesting feature of Chroma is embedding functions. You can see in the code that the function is never pushed to the server. It is simply passed into the constructor of the Collection class, which we will cover later.
Given this little information above, now let’s imagine for a second that you want to use the database in your production setup, likely with multiple clients. So which client wins when they both try to create a collection with different embedding functions? The answer is probably none, as the function is never stored along with embeddings. Essentially, the function is part of your client, and the client just happens to call it to obtain embeddings to further use them in queries. These functions are unrelated to the database.
Before we explore the Collection class, let’s take a quick look at the RESTful API server.
chromadb/server/fastapi/__init__.py#L53

This pretty much resembles the client’s API. And moreover, all the route handler methods call the corresponding methods of the client initialized in the constructor. Now this time the client is in the local mode. We can say that this may be considered an implementation of RPC to facilitate sharing state between multiple clients, excluding embedding functions…
To conclude with the clients, let’s also briefly look at the local client implementation:
chromadb/api/local.py#L49

Similarly to FastAPI, we see another layer of indirection. The DB class is ultimately responsible for managing document collections. We won’t cover rest of the methods here as they simply call the instance of DB. So this all boils down to two classes: DB and Collection. Let’s focus on the latter for now.
The Collection class represents a set of CRUD operations for a particular document collection, applying a given embedding function while changing or retrieving documents.
chromadb/api/models/Collection.py#L32

As you can see, the Collection class does some validation (hidden) and obtains embeddings from supplied documents and stores them via the client, whether it is local or rest. Other methods are alike - nothing fancy.
Now finally we are about to see the crucial component of the system, the DB class and its surroundings. The DB class is an abstract class and there are two concrete implementations for two kinds of underlying databases. Chroma supports Clickhouse and DuckDB, both are OLAP databases. Clickhouse is meant to be highly performant and scalable backend, whereas DuckDB is embedded and lightweight. Here’s the factory function responsible for initializing an instance of the DB class:
chromadb/__init__.py#L23-L56
