
Ray Serve Autoscaling
a journey into scaling decision making

https://github.com/ray-project/ray: 2.7.1 dated October 5th 2023.
With the obvious increase in adoption and application of open-source large language models, there is a rising need to effectively run their inference servers. The requirements may vary, but when it comes to the costs of the underlying infrastructure, particularly in cloud-based environments, the autoscaling capabilities are crucial.
Ray is a unified framework for scaling AI and Python applications. The framework has been around for years now and is widely popular. Serve, its model serving library, offers a versatile toolkit for deploying backend-agnostic services that can accommodate well-known ML frameworks as well as custom business logic.
If you’ve been wondering how autoscaling works in Ray Serve, you’ve come to the right place. Unlike our usual reviews that tend to cover the core functionality of a given product, this time we dive into a specific feature of a large system. Though, even a glimpse into the inner workings of Ray Serve may give you an idea how things are built at the abstract level. We will see some pieces of code in C++, Cython and Python.
Hello, World!
Let’s look at the Hello World example from the Quickstart section in the Ray Serve documentation.
import requests
from starlette.requests import Request
from typing import Dict
from ray import serve
# 1: Define a Ray Serve application.
@serve.deployment(route_prefix="/")
class MyModelDeployment:
def __init__(self, msg: str):
# Initialize model state: could be very large neural net weights.
self._msg = msg
def __call__(self, request: Request) -> Dict:
return {"result": self._msg}
app = MyModelDeployment.bind(msg="Hello world!")
# 2: Deploy the application locally.
serve.run(app)
# 3: Query the application and print the result.
print(requests.get("http://localhost:8000/").json())
# {'result': 'Hello world!'}It is a simple deployment that demonstrates how developers can serve their various APIs, including machine learning inference endpoints. We can assume that the deployment above spawns a single replica of the server, as we don’t see any related configuration. But does it scale? Specifically, can Ray Serve scale deployments up and down according to the load? And, can the framework scale them down to 0 replicas, which is quite relevant in the realm of costly GPU resources?
In this deep-dive review we are going to try to answer these questions.
Ray Serve deployments can be configured to enable the autoscaling functionality. According to its documentation, there are a few options that can be set to tune the autoscaling behavior:
min_replicas: the minimum number of replicas, which can be set to 0.max_replicas: the maximum number of replicas.max_concurrent_queries: the maximum number of ongoing requests allowed for a replica.target_num_ongoing_requests_per_replica: the average number of ongoing requests per replica.
There are additional options for further tuning, but the ones above are the primary ones. min_replicas and max_replicas represent the optional autoscaling boundaries, whereas target_num_ongoing_requests_per_replica and max_concurrent_queries might be perceived as soft and hard limits.
Now that we know how autoscaling for Ray Serve deployments can be configured using the options above, it is interesting to understand how those options are used underneath and how autoscaling decisions are made. But before we jump into the codebase, it might be worth getting acquainted with the high-level architecture of the system.
A Ray cluster consists of one head node and several worker nodes. A worker node is meant to run user-defined tasks and services. The head node is similar to a worker node, but has additional responsibilities for running cluster management components - the control plane.
Ray Serve relies on the actor system implemented in Ray Core. Within a Ray cluster, Ray Serve components run as actors that can perform remote procedure calls between each other. One such key component is ServeController which is responsible for the life-cycle management of its deployments, including scaling their replicas according to the provided configuration, handling updates, and ensuring high availability.
Ray Serve Architecture: Autoscaling

In Ray, an actor is a stateful worker process. Deployment replicas are long-running actors that perform tasks corresponding to incoming model inference requests.
Within a cluster, Ray Serve also runs one or more HTTP proxy actors, which serve as the ingress for HTTP traffic to the cluster.
We are now ready to dive into the codebase to see how the autoscaling logic in Ray Serve works. Usually here at Behind the Mutex we employ the top-to-bottom approach when we review the code: we start at an entry point and then dig deeper and deeper until we find the functionality in question. But this time we go the other way around and do the bottom-to-top review by focusing on a specific aspect deep in the codebase and going up until we see how the functionality is integrated.
Earlier we discovered the relevant deployment configuration options used for autoscaling decisions in Ray Serve. In particular, target_num_ongoing_requests_per_replica is the key option that the developers should provide to denote the capacity per replica. So, we have the target number. How do we get the current number to compare things with?
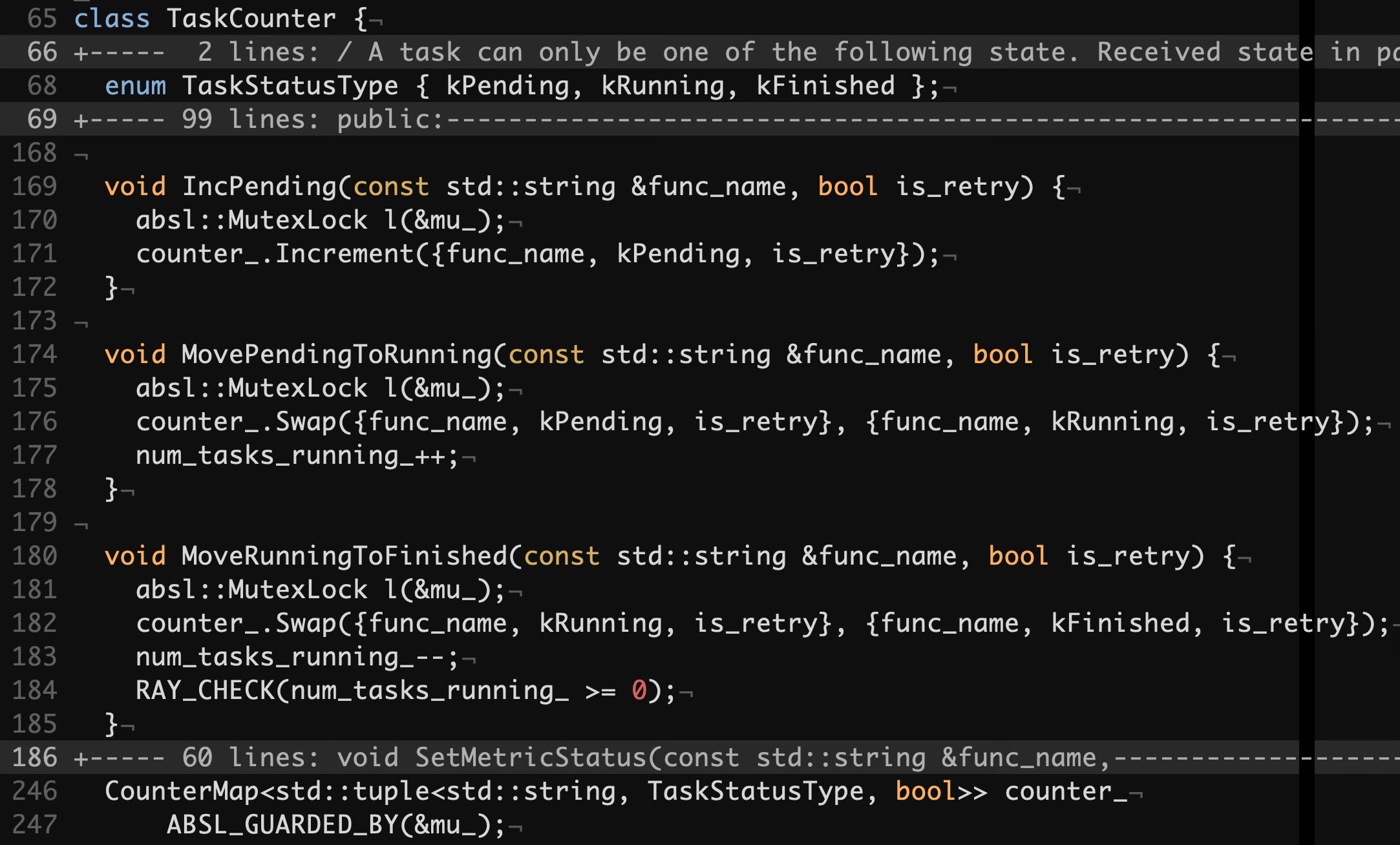
As stated above, a deployment replica is an actor. Actors are driven by CoreWorker, a C++ class that is responsible for task execution. Every instance of CoreWorker has a TaskCounter that tracks the numbers of pending, running and finished tasks. HTTP requests for model inference end up being processed by CoreWorker as actor tasks.
Below we can see the relevant parts of the TaskCounter class. It records the tasks’ function names, their statuses and transitions between them.
src/ray/core_worker/core_worker.h#L65
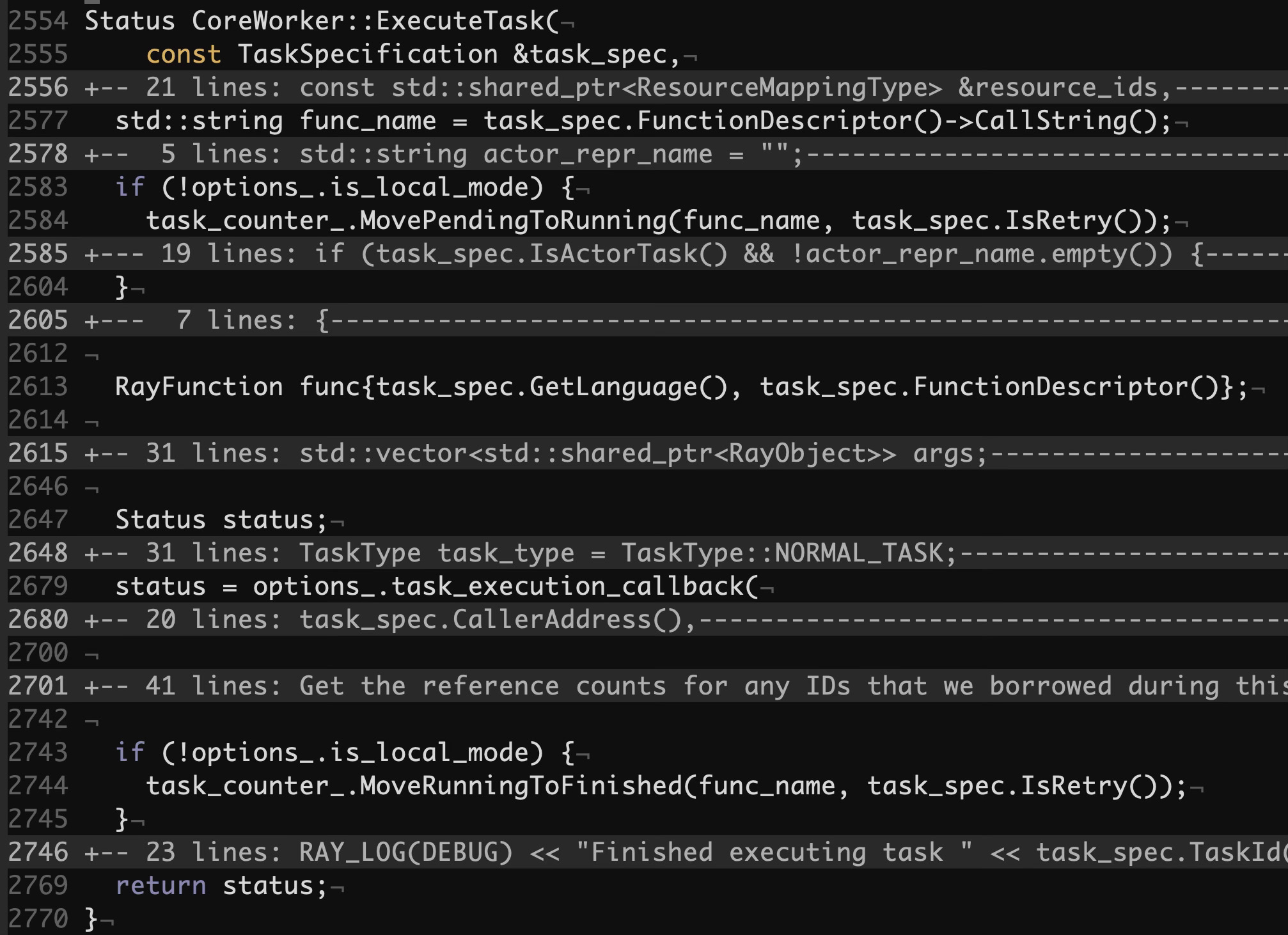
The methods above are integrated in the HandlePushTask and ExecuteTask methods within CoreWorker. Each task transitions from the pending to running and then the finished status. Here’s ExecuteTask that manages the task statuses:
src/ray/core_worker/core_worker.cc#L2554
Ok. TaskCounter holds the number of tasks with the mentioned statuses for each CoreWorker. Those numbers are collected centrally for each replica and for each deployment in ServeController. Let’s track how exactly this process is done.
CoreWorker implements the GetActorCallStats that returns a mapping of task function names to their corresponding aggregated stats per status.
src/ray/core_worker/core_worker.cc#L4125

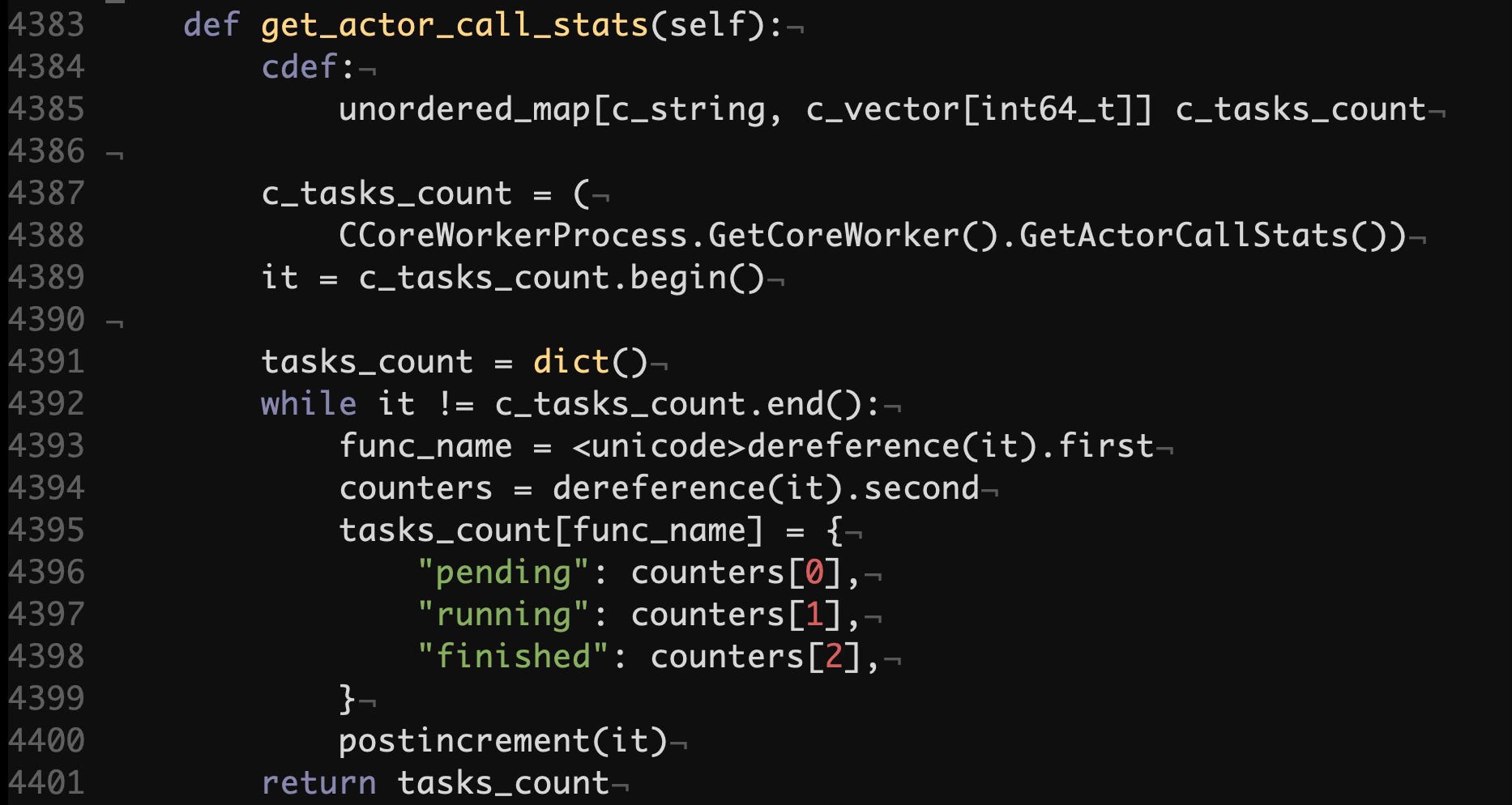
Below we can see a method in the Cython counterpart of the CoreWorker's C++ implementation. It runs within a raylet process on each node of the Ray cluster. This method simply transforms the mapping into a more nested version with explicit status names.
python/ray/_raylet.pyx#L4383
Next step - to find the piece of code that consumes those actor stats. RayServeReplica is the class responsible for executing the user-defined code. As part of the process, the instance periodically pushes its stats to ServeController. The MetricsPusher class used below maintains a dedicated thread that iterates over its registered tasks and executes them and their callback functions according to their configured intervals.
The RayServeReplica’s constructor registers a few of such tasks: